
Errors in Medin & Schaffer, 1978
Today we will simulate experiments on Context Theory of Classification Learning (Medin & Schaffer, 1978). Important differences between simulated and published results will be shown. Dr. Medin kindly confirmed the typos in the paper and asked to publish them somewhere.
Table of Contents
Set up the model
import numpy as np
def model(exemplars,trans_stim,exemplars_names,trans_stim_names,pars,An,Bn):
all_stim=np.concatenate((exemplars,trans_stim))
all_stim_names=np.concatenate((exemplars_names,trans_stim_names))
category =['A']*An
category.extend('B'*Bn)
category=np.array(category)
print "Stimulus number\t\tPredicted probability"
for i in range(len(all_stim)):
stim=all_stim[i]
stim_name=all_stim_names[i]
dists=abs(exemplars-stim)
sims=np.prod((1-dists)+dists*pars,axis=1)
simA=sum(sims[np.where(category=='A')[0]])
simALL=sum(sims)
prA=simA/simALL
print stim_name+'\t\t\t'+str(max([prA,1-prA]))
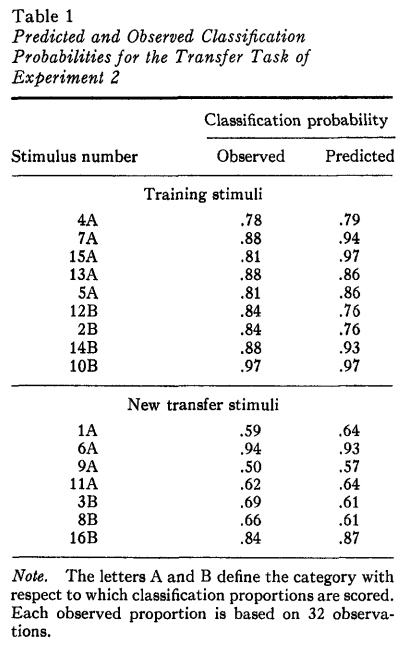
Experiment 2
exemplars=np.array([[1,1,1,0],[1,0,1,0],[1,0,1,1],[1,1,0,1],[0,1,1,1],[1,1,0,0],[0,1,1,0],[0,0,0,1],[0,0,0,0]])
trans_stim=np.array([[1,0,0,1],[1,1,1,1],[0,1,0,1],[0,0,1,1],[1,0,0,0],[0,0,1,0],[0,1,0,0]])
exemplars_names=np.array(['4A','7A','15A','13A','5A','12B','2B','14B','10B'])
trans_stim_names=np.array(['1A','6A','9A','11A','3B','8B','16B'])
pars=np.array([.16,.16,.18,.14])
model(exemplars,trans_stim,exemplars_names,trans_stim_names,pars,5,4)
Stimulus number Predicted probability
4A 0.780826893395
7A 0.937461286104
15A 0.967828145282
13A 0.862532220995
5A 0.859324492861
12B 0.747772198851
2B 0.76110945422
14B 0.92887283743
10B 0.963648568404
1A 0.645347147878
6A 0.926105712059
9A 0.602958902172
11A 0.605683339728
3B 0.574466033716
8B 0.615471548188
16B 0.864824603505
When we compare the answers with the Table 1 from the paper, we will see the differences in stimuli 9A, 11A, 3B.
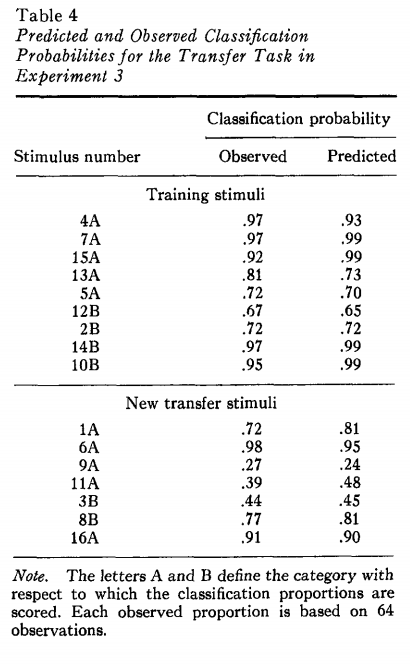
Experiment 3
exemplars=np.array([[1,1,1,0],[1,0,1,0],[1,0,1,1],[1,1,0,1],[0,1,1,1],[1,1,0,0],[0,1,1,0],[0,0,0,1],[0,0,0,0]])
trans_stim=np.array([[1,0,0,1],[1,1,1,1],[0,1,0,1],[0,0,1,1],[1,0,0,0],[0,0,1,0],[0,1,0,0]])
exemplars_names=np.array(['4A','7A','15A','13A','5A','12B','2B','14B','10B'])
trans_stim_names=np.array(['1A','6A','9B','11B','3A','8B','16A'])
pars=np.array([.00,.20,.10,.40])
model(exemplars,trans_stim,exemplars_names,trans_stim_names,pars,5,4)
Stimulus number Predicted probability
4A 0.929577464789
7A 0.987714987715
15A 0.994694960212
13A 0.727520435967
5A 0.700280112045
12B 0.65445026178
2B 0.719887955182
14B 0.985994397759
10B 0.994397759104
1A 0.81308411215
6A 0.951219512195
9B 0.761904761905
11B 0.52380952381
3A 0.545454545455
8B 0.809523809524
16A 0.904761904762
Experiment 3 seems to be fine. If we compare the output with Table 4, there are no major differences.
Note: Stimuli probability of 9A=1-probability of 9B, 11A=1-probability of 11B, 3B=probability of 3A
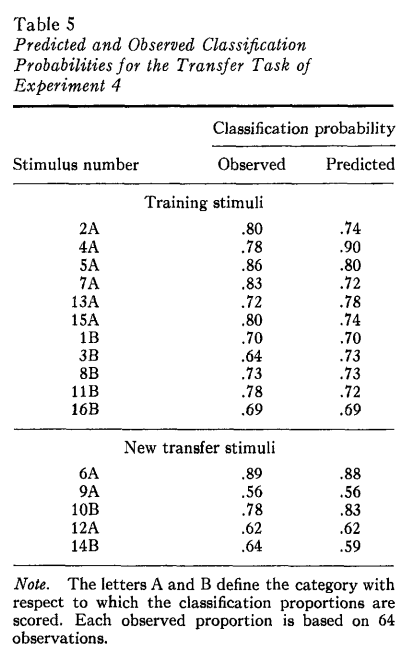
Experiment 4
exemplars=np.array([[0,1,1,0],[1,1,1,0],[0,1,1,1],[1,0,1,0],[1,1,0,1],[1,0,1,1],[1,0,0,1],
[1,0,0,0],[0,0,1,0],[0,0,1,1],[0,1,0,0]])
trans_stim=np.array([[1,1,1,1],[0,1,0,1],[0,0,0,0],[1,1,0,0],[0,0,0,1]])
exemplars_names=np.array(['2A','4A','5A','7A','13A','15A','1B','3B','8B','11B','16B'])
trans_stim_names=np.array(['6A','9A','10B','12A','14B'])
pars=np.array([.18,.20,.28,.33])
model(exemplars,trans_stim,exemplars_names,trans_stim_names,pars,6,5)
Stimulus number Predicted probability
2A 0.737850144598
4A 0.902426350985
5A 0.800048873711
7A 0.719651615695
13A 0.78457274996
15A 0.709160974643
1B 0.699837631502
3B 0.73835719656
8B 0.727331192801
11B 0.728566781548
16B 0.693685604349
6A 0.889195721911
9A 0.562852049249
10B 0.832383171054
12A 0.620613246937
14B 0.789389340146
These results are also different from the published, specifically for stimuli 15A and 14B.
Reference: Medin, D. L., & Schaffer, M. M. (1978). Context theory of classification learning. Psychological review, 85(3), 207.